SEOのベースになるクローラー(Crawler)という単語を、一度は聞いたことがある人は多いのではないでしょうか。
検索キーワードの上位表示は、Webマーケティングに関わる人にとっては、重要なテーマです。
コンテンツのクオリティが最重要なことはわかっていても、そのメカニズムは意外と知られていません。
本記事では、その仕組みについて解説していきます。
1. クローラー(Crawler)とは
クローラー(Crawler)とは、インターネット上のテキストデータや画像データを周期的に収集し、自動的に検索データベース化する巡回プログラムのことです。元の語源である「Web上を這う=クロールする」から、「クローラー」と呼ばれています。
ロボット型である検索エンジンは、多数のクローラーを派遣して、世界中の膨大なWebサイトの情報を収集しています。クローラーは情報を収集すると、検索エンジンに戻り、その情報を整理してデータベースに記録します。
Webサイトのページがクローラーに情報収集され、検索エンジンのデータベースに記録されている状態が、SEO用語の「インデックス」です。
新規ドメインで新しくホームページを立ち上げた場合、検索結果に反映されない現象が起こるのは、検索エンジンのクローラーがまだそのホームページを見つけていないからなのです。
(※Google Search Consoleに登録し、管理画面の「URL検査」にURLを入力することで、インデックス登録を促進することができます)
※関連コンテンツ
・Googleへの登録(インデックス)の方法
2. クローラーの情報収集から検索エンジン登録の流れ
クローラーの情報収集から検索結果表示までの一連の流れのことを、クローリングといいます。その流れは、どうなっているのでしょうか。
1. クローラーが検索エンジンのデータベースに登録されているWebサイトに到着し、リンクを辿って巡回します
2. ページにたどり着くと、ページの情報を解析&データ変換します
3. そのデータを、検索エンジン本体のデータベースに登録します
クローラーは、既に認知しているWebサイト(HTML)のリンクを辿り、別のデータを収集するという動きを繰り返します。インターネットの世界に張り巡らされている情報ネットワークが蜘蛛の巣のように見え、クローラーはその蜘蛛の巣を自由に渡り歩くように見えるため、「スパイダー」と呼ばれることもあります。この張り巡らされた情報網を自動的に巡回し、膨大な量を収集していきます。
クローラーはプログラムなので、テキストデータしか読み込むことはできません。クローラーは、人が目で見て判断するデザインや画像の中身を認識することは不可能です。
実際に収集するデータの種類は、以下のようなものです。
【クローラーの情報収集対象】
・Webサイトの文字部分
・PHPファイル
・JavaScriptで生成されるリンク
・Flashの中にあるリンク
・PDF
・Word、PowerPointによって作成されたファイル
3. 有名なクローラー
3-1. Googlebot(Google)
Googlebotは、Googleのサーチエンジンが検索用にインデックスを作成するために、Webサイト上を巡回し、テキストやリンクデータを収集しています。
これとは別に、携帯電話向けサイトの情報を取集するGooglebot-Mobileもあります。Googlebot-Mobileは、Samsung SGH-E250、Nokia 6820など、携帯電話の機種名がついているのが大きな特徴です。
巡回して集めた情報をGoogleはプログラムによって信用度や重要度、権威性などによってランキングしていますが、そのアルゴリズムは企業秘密として公開されていません。
3-2. Bingbot(マイクロソフトが運営するbing)
Bingbotは、マイクロソフトが運営する検索エンジンBingで使われているクローラーです。
2013年にGooglebotに引き続き、Bingbotが巡回するようになりました。5種類のBingbotが稼働しているといわれています。その特徴はクロール回数が多く、ページ数が多く更新頻度が高いWebサイトほど、Bingbotの巡回回数は増える傾向のようです。
3-3. Yahoo Slurp
Yahoo Slurpは、Yhaoo!の検索エンジンTSTで使われているクローラーです。
もともとは、Yahooが買収したInktomi社が提供していた検索エンジンのクローラーです。なお、日本のYahoo!の検索はGoogleと同じシステムをしており、Yahoo Slurpは使用されていません。
4. 自社サイトがクローラーに認識されているかチェックする
4-1. 自社Webサイトの状況を把握する
新規ドメインでアップした場合など、自社のWebサイトが検索表示に反映されないことが多々あります。自社のWebサイトにクローラーが来ているのか、その結果検索エンジンのデータベースにどの程度インデックスされているのか、その状況を把握しましょう。
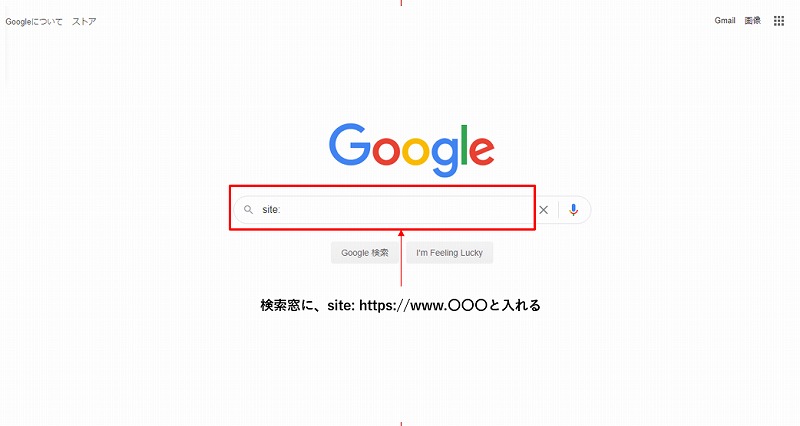
4-2. クローリングを開始させる方法
新しいWebサイトをアップした時や新たなコンテンツを追加した時、クローリングを開始させる必要があります。そのためには、Googleに知らせる必要があります。効果的なのは、サイトマップをGoogleに提供する方法です。
具体的にはWebサイトのすべてのページのURLを記載したxml形式のファイル「sitemap.xml」をGoogle Search Console経由でGoogleに提供します。以下の情報がわかる仕様になっています。
・URL情報
・更新頻度
・最終更新日
【クローリングを開始させる方法/Google Search Console編】
1. sitemap.xmlを作成する
2. Google Search Consoleにログイン
3. 画面左側のタブにある「クロール」>「サイトマップ」をクリック
4. 右上にある「サイトマップの追加/テスト」をクリック
5. 入力欄にXML形式で入力し、「サイトマップを送信」を押す
4-3. クローラーの動きを確認する方法
検索エンジンのクローラーが、自社のWebサイトをどれくらいの頻度で巡回しているか、気になりますよね。これも、Google Search Consoleを活用することで、動きを確認できます。
【クローラーの巡回の状況を確認する方法】
1. Google Search Consoleにログイン
2. 「クロール」>「クロールの統計情報」をクリック
ここでは、以下の情報が確認できます。
・1日あたりのクロールされたページ数
・1日あたりのダウンロードされたページのKB数
・1日あたりのページのダウンロード時間
また画面左側の「Google インデックス」>「インデックスステータス」をクリックすると、インデックスされたページ数をグラフの形でみることができます。
4-4. クローラーの効率を上げる方法
クローラーの効率を上げるには、様々な手法があります。その代表的な手法を、以下に記します。
【クローラーの効率を上げる方法】
・コンテンツのURLにキーワードを入れ、できるだけ短く設定する
・URLの重複があれば、修正する
・TOPページから2クリックで、全てのページに飛べる構造にする
・画像リンクではなく、テキストでのリンクを設定する
・ユーザーが今どこにいるかがわかる「パンくずリスト」を設定する
・ページネーションは、「次のページ」ではなく、「1」「2」「3」のように数字で表記する
・アンカーテキストは、「こちらへ」ではなく、「ユーザビリティについてはこちら」のように具体的に書く
5. まとめ
今やユーザーに支持される良質なコンテンツによる検索上位表示は、Web担当者にとって必須のテーマになりました。
あらゆるジャンルのビジネスがインターネットを介して行われる以上、検索上位表示がどのようなメカニズムで運営されているのか、また自社のWebサイトがどういった状況なのかをを把握しておくことはとても重要です。
現在のWebマーケティングは、全ての現象が数値化することが可能です。
だからこそ、その数値の意味と施策と変化率の相関関係を習得し、日々アップデートすることが重要なスキルになってきます。